

Email Classification into relevant labels using Neural Networks
This research work has been carried out jointly by Deepak Kumar Gupta & Shruti Goyal
November 11, 2017
Copyright Notice: Any redistribution or reproduction of part or all of the contents in any form is prohibited other than the following:
- you may print or download to a local hard disk extract for your personal and non-commercial use only
- you may copy the content to individual third parties for their personal use, but only if you acknowledge the website as the source of the material
Abstract
In the real world, many online shopping websites or service provider have single email-id where customers can send their query, concern etc. At the back-end service provider receive million of emails every week, how they can identify which email is belonged of a particular department? This paper presents an artificial neural network (ANN) model that is used to solve this problem and experiments are carried out on user personal Gmail emails datasets. This problem can be generalised as typical Text Classification or Categorization [8].
Keywords: Artificial Neural Network, Email Classification, Natural Computing, Text Categorization
1 Introduction
Electronic mail or e-mail is a method of electronic communication between two or more users using the Internet. Nowadays emails are not just used for communication but also used for managing the task, solving customer queries. Email Classification or Categorization has been inspired from the text categorization in machine learning (Supervised) and now email classification has been adopted in different variations such as categorising emails into a pre-defined folder, blocking spam email, identifying the tone of the consumer from email content etc. Latest email application and the service provider such as Gmail, Outlook allow the user a simple method of filtering incoming emails based on the email subject, keywords in the body, this method best suitable for personal work or home users, which means one need to create keyword-based rules to filter emails into different folders. Implementing or Creating these rules manually in email software can be difficult if one wants to categorise each incoming emails. X. Carreras and L. Marquez [2] noted that most users waste a large amount of time in managing their emails or they simply do not prefer to create keyword-based rules to filter emails in their inbox.
Today, in the world of big data, the volume of emails growing so fast. As per Radicati [6] , in 2016, there was 2672 million email user who exchanged about 215.3 billion emails per day. It is estimated by The Radicati Group [6] that email database will grow by 4.7%. Consider a large e-commerce website which has about the active customer base of 200 million and supposes at least 10% customer make a purchase every month. Gaint e-commerce like Amazon, eBay etc generally has a common email address (cs@amazon.com) for all kind of queries. It means that an e-commerce company must be getting about 100000 emails every month (considering 10% customer do write emails), therefore a company requires a big database to store all emails and a system which can automatically identify/classify an email into correct department categories such as Refunds, Shipping, Quality Issues etc.
A customer support manager who is responsible for assigning thousands of emails to respective teams so that quick solutions and service can be provided to the customer. Imagine how much time one has to spend if a company gets millions of e-mails during Boxing Day or Black Friday sale. Companies do need a system which can automatically classify or assign a label to an email. However, To provide customer support using email communication channel one need a model or system which learns from the previous dataset and categorise new emails with higher accuracy is very much desired by companies.
This study investigates and carried out experiments to find out how artificial neural networks algorithm can be utilised for email classification.
2 Artificial Neural Networks
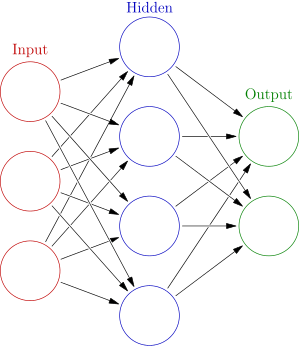
Artificial Neural Networks (ANNs) can resemble with the human brain. The key element of a neural network is a general model of a Neuron Perceptron Fig. 1. A neural network consists of a set of neurons and each neuron is connected to one or more neurons in a direct manner. Anderson, Dave and McNeill, George[1] noted that an artificial neural network consists of multiple inputs which can be represented with the help of symbol, x(n) Fig. 2 and these inputs directly fed into the network. Information from inputs is weighted w(n) Fig. 2 before sending to next level layers i.e hidden layers depending on the number of hidden layers in a network. Connection weight of each input is summed and then directly fed via a transfer function to produce final output i.e. classification of data.

Figure 2: Neural Network Architecture
There are three types of learning for an ANNs: Supervised, Unsupervised and Reinforced. Supervised learning is more commonly used for training a neural network for a given dataset. One can train the perceptron with supervised learning in ANNs by calibrating the inputs weights. For supervised learning, training dataset already has predefined labels or category for given input weights. Each training dataset is fed into perceptron which performs some computation and then generates an output. The output result is matched against predefined class/label, no input weight adjusted if it’s a match otherwise input weight slightly modified according to the expected final results. The process is repeated number of time so that model can be trained with higher accuracy. As per [9] ”The most appropriate point to stop training may be the point at which the reduction of Mean Square Error (MSE) becomes marginal.”
A propositional algorithm developed by Cohen [4] called RIPPER to categorising emails into folders based on ”keyword-spotting rules”. Cohen also said that keyword spotting rules are easy to create, update and reuse. On the other hand, Sahami [7] did classification of Spam emails using a bag of words by applying the naive Bayesian algorithm.
3 Methodology
3.1 About Dataset
To perform experiments on neural network for email classification, personal Gmail inbox data has been imported. In this data, each email has been assigned a pre-defined class/category using Gmail TM label feature and dataset has 608 emails.
Table 1: Label Email Count Breakdown
Label Count
bvp 102
corprova2011 238
deepak891@gmail.com 73
Inbox 47
deepakg@live.com 21
Imagic 91
Placement 8
TCS 11
Total emails 608
3.2 Model Setup
This experiment has been carried out on a neural network which is build using Keras [3] as a back-end, as Keras provide a playground that facilitates easy and fast implementation using Python to carry out deep learning experiment in a jiffy. Keras convert emails into a numeric matrix by assigning a rank based on the number of times a word appeared, thereafter converting the number into vectors which represent the label of each email. A neural network can be trained by consuming this data with LSTM ( Long Short Term Memory) to correct categorise new emails. But, by extracting best and bad features for each email, neural net accuracy improved. To extract features from the text, Keras tokenizer class allow us to do so.
begin{verbatim}
Label word breakdown:
Bank:4
bvp_:7441
Sent:1561
Unread:6810
corprova2011:10932
deepak891@gmail.com:3880
Inbox:4244
Starred:60
deepakg@live.com:1093
Google:347
Imagic:3982
MyUnplugged:34
Placement:401
TCS:1202
Total word count: 42219
Figure 3: Output: Word Count for each Label in dataset
4 Experiments & Results
Experimental data used is from first author personal Gmail inbox. Initially, the dataset has been cleaned and synthesised for the consumption of ANNs and labels which do not have enough number of emails has been removed. Such
emails will not contribute much in training of the model. The model has been trained using 548 (90.13%) emails and 60 (9.86%) emails used for validating the model. Two experiments carried out to measure the performance of the model for different input parameters and the number of words selection.
4.1 Experiment #1
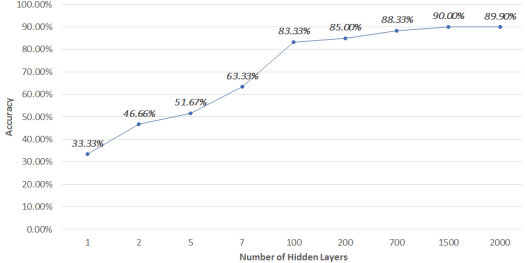
In this experiment number of words, the ratio has been fixed while the number of hidden layers changed to test the performance of the neural network with an increase in the number of hidden layers. When HN = 1 (Number of Hidden
Layers), the accuracy achieved was 33%, which is very poor but when hidden layers increased linearly, it is observed that accuracy of algorithm increased to 85% when HN = 100.
For HN ≥ 100, accuracy didn’t improve much, but best accuracy achieved was 90% when HN = 1500. In Fig. 5, it is clear that accuracy line is almost parallel to the x-axis from HN = 100 to HN = 2000. We can verify that
accuracy of the neural network to correctly classify improves with an increase in the number of hidden layers [10].
4.2 Experiment #2
Table 2: Accuracy vs Number of Words selection
Number of Words No. of Hidden Layers Accuracy
5500 100 81.67%
12000 100 88.33%
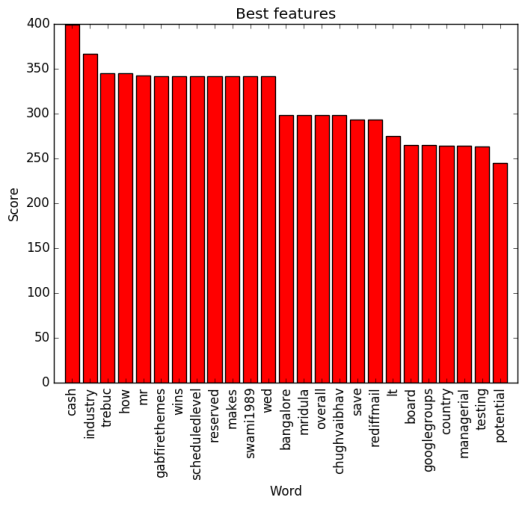
In this model of ANNs (Artificial Neural Network), English helping verbs and conjunction words such as and, what, of etc. have been excluded from the data stream as such words wont add much in improving the accuracy of the classification model. Moreover, such words may deviate the actual results. The second experiment has been performed to see, how the algorithm performs when a number of words feed into ANNs vary. It can be noted from Table 2 that accuracy of the model is improved by 6.67% when num words (number of words) value is increased by 118%. It is understood from the test that when a large number of words is feed into the neural network, model prediction accuracy increased.
This model selects the best feature words based on chi-square using Scikit library. Word features selection allow the model to exclude less significant words from dataset to improve model correctness and data processing time, as the model is configured to not to include words which are not significant.
5 Conclusions
During experiments, it is noted that more words in an email lead to better accuracy while keeping algorithm processing time lower. Datasets don’t have enough number of email labelled for ’Shruti’ and ’TCS’. From confusion matrix [5] in Fig. 6, it is seen that the model able to accurately classify labels for all email categories except for labels ’Shruti’ and ’TCS’. After conducting two experiments, it is concluded that large dataset is required to train the model for classifying emails into the folder with high accuracy and model trained with more words selection has higher accuracy compared to the model which is trained with less number of words.

The diagonal line in Fig. 6 has dark coloured patches mean that the true positive value of each label is accurately classified by the model. One can further improvise this algorithm by customising it for particular use Figure 6: Confusion Matrix for Exp case scenarios such us Customer Support, CEO Email Management, Enterprise level user etc.
6 Acknowledgements
The first author would like to thank Prof Michael O’Neill, Dr Mike Fenton, Dr David Fagan for their help and support.
References
[1] D. Anderson and G. McNeill. Artificial neural networks technology. Kaman Sciences Corporation, 258(6):1–83, 1992.
[2] X. Carreras and L. Marquez. Boosting trees for anti-spam email filtering.arXiv preprint cs/0109015, 2001.
[3] F. Chollet et al. Keras, 2015.
[4] W. W. Cohen et al. Learning rules that classify e-mail. In AAAI spring symposium on machine learning in information access, volume 18, page 25.California, 1996.
[5] G. Csurka, C. Dance, L. Fan, J. Willamowski, and C. Bray. Visual categorization with bags of keypoints. In Workshop on statistical learning in computer vision, ECCV, volume 1, pages 1–2. Prague, 2004.
[6] J. Levenstein. Email statistics report, 2013-2017. The Radicati Group,Inc., Palo Alto, CA, 2013.
[7] M. Sahami, S. Dumais, D. Heckerman, and E. Horvitz. A bayesian approach to filtering junk e-mail. In Learning for Text Categorization: Papers from the 1998 workshop, volume 62, pages 98–105, 1998.
[8] F. Sebastiani. Machine learning in automated text categorization. ACM computing surveys (CSUR), 34(1):1–47, 2002.
[9] Y. Shao, G. N. Taff, and S. J. Walsh. Comparison of early stopping criteria for neural-network-based subpixel classification. IEEE Geoscience and Remote Sensing Letters, 8(1):113–117, 2011.
[10] A. J. Surkan and J. C. Singleton. Neural networks for bond rating improved by multiple hidden layers. In Neural Networks, 1990., 1990 IJCNN International Joint Conference on, pages 157–162. IEEE, 1990.
